When creating any kind of data warehouse or lakehouse you need at least three steps. You get the data from the source systems (often called ingestion or extraction), you clean the data and apply some business logic, and you model the data for consumption. For data warehouse it is called ETL (Extract, Transform and Load) or ELT (Extract, Load, Transform). Not much is different with lakehouses, you might do more steps, but the general concepts are the same.
One of the most important steps is transforming the data or applying business logic. Data does rarely come from the source system ready for analysis. Some logic needs to be applied to transform and shape it ready for analysis. When creating traditional data warehouses in SQL Server most developers used either Stored Procedures or views to store the transformation logic.
Options for storing business logic in Microsoft Fabric lakehouse
Things are slightly different with lakehouses in Fabric. You still have multiple ways to store your transformation logic. Below I will try to go through the most common ones and talk about the pros and cons of each.
Notebooks
You can store the logic in notebooks. This is similar to creating a stored procedure in SQL Server. You create one notebook per table and write the logic in there. One of the pros of this method is that it´s very explicit. Each notebook has one purpose and it´s easy to understand where the logic is kept. Another pro is that you can write the logic in verity of languages. The main con is that you might end up with a lot of notebooks if you have a lot of tables.
Views in the SQL endpoint
You can store your logic in views in the SQL Endpoint. This allows you to write your views in a familiar SQL language. This is exactly as using views in SQL Server. The pros of this method are that it´s very explicit. You have one view per table and it´s easy to see where the logic is. Another pro is that lot of developers know SQL and find it comfortable to work with. One of the main pro is that you can have a generic notebook which loops through the views and applies the logic to the tables. Another pro is that you can use either notebooks or Data Factory when moving the data to the next stage. One of the cons is that you will potentially have lot of views if you have lot of tables. Another major con at this point in time (September 2024) is that the only way you can query SQL views via notebook is with a connector to the SQL endpoint and warehouse from Microsoft (see more information here: https://learn.microsoft.com/en-us/fabric/data-engineering/spark-data-warehouse-connector). There are several limitations to the connector at the present time. One major is that you can only use Scala to connect to and read from the SQL endpoints. Another one is that you can only query the whole table or view. No custom query is allowed. This last one shouldn´t be too much of a problem for storing business logic as the view should be only what is necessary. At the time of this writing (September 2024) the connector is quite unstable but that will hopefully get fixed very soon.
Spark views
Similar to SQL views Spark has a concept of permanent views as well. You can write them in Spark SQL and they work the same as SQL views. If you prefer to use other languages than Spark SQL you can build a dataframe in other languages and then write the view using Spark SQL giving you the flexibility of Spark and the convenience of SQL. One of the pros of this method is that it´s very explicit. You have one view per table making it easy to see where the logic is. Another pro is that you get the full flexibility of Spark. The cons are that you might end up with a lot of views if you have a lot of tables. Another con is that these Spark views are not visible anywhere in the UI. The only way you can discover them is via code.
Files or database
You can store your business logic as code in files or databases. You could for an example store the logic in JSON files and query it from there at runtime. Similarly, you could store the logic in a column in a database and query that at runtime. One of the pros of this method is that you separate your workload from your logic. The logic can be edited outside of your Fabric environment. Done well a subject matter expert without any Fabric knowledge can maintain the logic. The cons are that it can be complex to maintain complex logic in files or database columns. It needs to be planned and executed well to work properly.
What to choose
So, what to choose. There is no one correct answer. It depends a lot on your requirements. At present time (September 2024) I would recommend using either notebooks or Spark views to store the logic. I will use either option if I want to use Data Factory to orchestrate the data load and notebooks if I want to use MSSparkUtil to orchestrate the data load. When it becomes easier to work with SQL views in notebooks, I might consider using them but the only reason I would use them at present is if I use Pipelines to read and write the data.
I hope this article helps you understand the possibilities of where to store your business logic in Microsoft Fabric. Please leave comments if you have anything to add or get in touch if you want to hear how we can help you work with Microsoft Fabric.
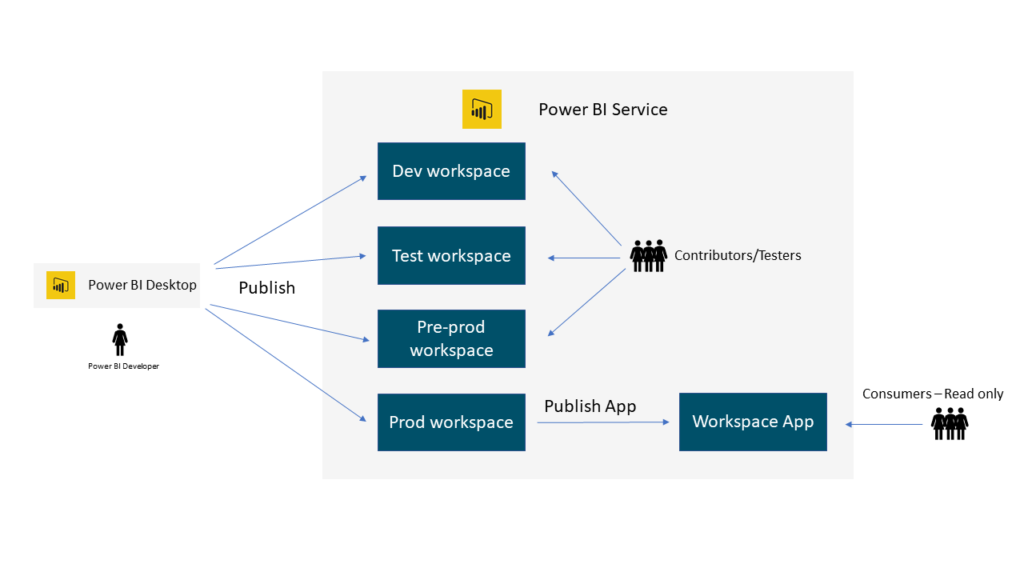
I´m delivering a Microsoft Fabric project for a customer and we had some great discussions about what strategy we should follow for workspaces. This blog post is those discussions boiled down to couple of pages 😊
When deciding on a workspace strategy for Microsoft Fabric there are several, often conflicting, things to consider.
One is ease of maintenance. The fewer workspace the easier it is to maintain and manage.
Other considerations are segregation of duties, isolation of workloads and security isolation. These call for many workspaces.
Where on the scale an organization ends, is dependent on what is important to the organization and what kind of balance they want to reach.
Things that impact number of workspaces:
Number of environments (dev, test, pre-prod, prod etc.)
Number of stages (extract, staging, dw, mart etc,)
Isolation of workload resources from each other (Data Factory doesn´t use resources for Spark or wise versa)
Security consideration (developers are not allowed to see production, those doing ingestion should not be able to modify Spark code etc.)
Ways of working with DevOps (one branch per workspace limitation in Fabric)
What are the outer number of workspaces?
It´s possible to have everything in one workspace but realistically you will always end with at least one workspace per environment (dev, test, prod) or at a minimum one for prod and one for rest. So, the minimum number of workspaces is 2-3.
At the other end of the scale, each workload will have one workspace per environment and each feature will have one workspace. If we imagine that we use Data Factory to ingest data into extract lakehouse, then we use Spark to clean and transform the data into staging lakehouse, then we use Spark to load the data into DW lakehouse, then we build a Power BI semantic model and finally reports on top of that. We then have 3 workspaces for each workload (assuming dev, test and prod). 3 for Data Factory, 3 for the extract lakehouse, 3 for the staging lakehouses, 3 for the dw lakehouses, 3 for the semantic models and 3 for reports. This gives us 15 workspaces. Add to that one workspace per developer for each of the workspaces if you decide to branch the workspace during development. These branch workspaces are temporary while the development happens and are most likely only accessed by the individual developer.
Other things to consider
How your team is compromised will be a deciding factor in what strategy you decide on. If you have a small team of developers which are developing the whole pipeline from ingestion to transformation to semantic models you can use fewer workspace than if you have dedicated developers for each workload. It´s also about trust. If you trust your developers not to mess with each other’s code, you can have fewer workspaces. If you feel you need to isolate workloads from each other, you will need more workspaces.
Therefore, there is no one rule for how many workspaces you should have. In my opinion you should be pragmatic about it and try to weigh the need for workload isolation and strict CI/CD protocols against ease of maintenance and development.
Impact of CI/CD on workspace stragegy
If you decide to use CI/CD for your Fabric development, you need to decide how your developers are going to work. You can only have one branch per workspace. This means that if you have more than one feature you want to work on, you need to decide if you work on all of them in one branch (workspace) or if you want to have one branch (workspace) per feature.
My recommendation is to have one branch (workspace) per feature and then when the feature is complete you merge that into the main branch which is connected to your development workspace. It´s important that you clean up the feature workspaces so you don´t end up with hundreds of dormant workspaces with the code in different stages.
At the moment the only way to deploy is via Fabric Deployment Pipelines. Therefore, this is the recommended way to deploy. If and when there are APIs for deployment of Fabric items, you can consider building your own deployment pipeline.
Where did we end with this particular customer?
We decided to go with one workspace per stage per environment. 3 environments (dev, test and prod) and 3 stages (extract, staging, dw) in the Lakehouse. Semantic models will have one workspace per environment. Reports were kept out of the scope as they are not developed frequently by the central team. We therefore will end with 12 workspaces plus workspace per feature while it´s being developed.
The news is out, the cat is out of the bag, the secret has been revealed!
If you haven´t noticed Microsoft revealed their new lake-centric software-as-a-service solution for data analytics. It´s a one stop shop for data integration, data engineering, data warehousing, data science, real-time analytics, applied observability, and business intelligence. It´s built on a data lake using the open delta file format.
You might be thinking, why invent the wheel when they have a bunch of good solutions already? The answer to that is that they are not. They are taking the good things from Synapse Analytics, Azure Data Factory and Power BI and adding a new monitoring solution. But it´s not just taking those solution as-is. The foundation of the platform is OneLake a data lake based on the delta file format. It´s called OneLake as you should only have one copy of your data and all workloads (spark, sql, real time analytics or data science) as well as Power BI will all work on top of the same copy of the data. Even for Power BI you don´t have to import the data anymore (if your data is in the OneLake).
The Synapse tools will now all work directly on the lake, even the Data Warehouse part.
So, what does it mean for you and how do you get started?
I have been so fortunate to be able to test out these solutions for the past few months. It´s very promising. I´ve not tested production workloads but what I have seen I like. It´s only preview, and some of the stuff is pretty revolutionary, so there have been some issues but overall, I´ve been impressed. I´m not saying you should drop your current solution and move everything to Microsoft Fabric, but you should start looking into what it is and where it might benefit you. I see huge potential in the platform for all sizes of organizations. I think companies of any size, even SME´s are going to see some cost savings and I think it´s going to save a lot of time because you don´t need to move as much data around. You are still going to be doing the same architecture (that never really changes) which is great.
What I really like about it is that you can have mixed workspaces with fx. a spark notebooks, data factory pipelines and Power BI reports. So if you work across you can stay in one workspace. It might also make it easier to work as a team in one workspace. I still think that for many IT teams you will have different workspaces for different workloads/personas/tools but there will be times when it makes sense to have some or all of it in one workspace.
My advice to you is to take it easy. Find a good scenario where you can test out the capabilities over the next few months and be ready to take advantage of the platform when it becomes generally available. I´m hoping for an easy “migration” path from Synapse Analytics and Azure Data Factory. I´m assuming that if you have a data lake already it should be fairly straightforward to move that into the OneLake but I´m not sure at this point in time as I have only tested copy/pasting.
How do you get started?
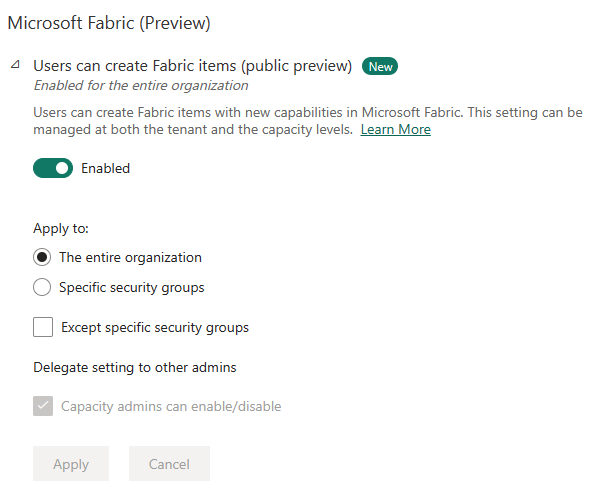
Before you can get started you need to turn Microsoft Fabric on in the Power BI tenant settings. You can turn it on for the whole organization (I don´t recommended that at this point in time) or for a subset of the organization through specific security group(s). Not that it´s off by default but if you don´t touch it Microsoft are going to turn it on for everyone sometime in June.
When the setting is turned on, there are two ways to get started with Microsoft Fabric.
If you have existing Power BI capacity it will be converted to Microsoft Fabric capacity, and you can use it for all the other workloads (during the free preview you won´t actually use your capacity but you can monitor how the workloads would affect your capacity). If you don´t have Power BI you can start a free 60 day Microsoft Fabric trial and get free capacity during that. You need to go to https://app.fabric.microsoft.com/. There you can click on your user image in the top right corner. There will be a start trial button there you can press to start your trial.
After you “turn fabric on” you can work with the different components on https://app.fabric.microsoft.com/ or on https://app.powerbi.com/ via the icon at the very bottom on the left. Clicking that will allow you to choose a tool to work with.
I will be posting more as I test out more production like scenarios in the coming months, so stay tuned.
This summer has been very eventful for me and my family and not just because of the world pandemic. Some of you might have noticed that I haven´t been very active in blogging or on social media for couple of months. This is due to some happy personal situations.
To recount what has happened we need to start by going back to June. On June 24th we had our third child. She´s fantastic and perfect like her older sisters. It´s been 11 years since our middle one was born so it took some time getting back into the baby parenting role again but I´m thoroughly enjoying it.
On August 1st we moved from Iceland to Denmark. We had been planning the move for a while as we wanted to be closer to my wife’s family as I travel quite a bit (or I used to at least). The plan was to move at the end of May when our older daughters were done with exams in their school but before our youngest was born. Unfortunately, the COVID-19 pandemic prevented us from taking to Denmark to look at houses. I managed to do that on June 15th, less than a week before the expected birthdate. My wife and I made a pact. I would find us the perfect house and she would keep the baby in until I came back. Both things worked out as planned ?. It´s a big thing moving between countries separated by an ocean. You need to pack your stuff into a shipping container two weeks before you want to receive it in the new house. This meant we risked being homeless for 14 days with a newborn. Luckily my sister could loan us an apartment, so it worked out well.
These two big events took all my energy in the last 2-3 months as you might understand.
Now I´m back to full work and ready to start to contribute more to the community and participate more.
While I was in my online hiatus some great professional things happened as well.
My MVP award got renewed for the third time
I got selected to speak at PASS Summit
I got selected to speak at SQL Saturday Gothenburg on September 5th (really looking forward to that one)
I´m still speaking at SQL Bits although now virtual. I have a training day that I´m adapting to online delivery. That is going to be awesome.
#DataWeekender #TheSQL has opened call for speaker.
Me and Michael Johnson finished the first draft of the book we are writing
Expect to see some posts about the coming events from me and also some posts where I continue my series on Power BI monitoring and governance.
If you like to connect or get in touch you can subscribe to my newsletter in the box to the right or find me on social media. If you like to see what we have to offer you can navigate to https://northinsights.com
Power BI is essentially a self-service BI tool where users traditionally have a lot of freedom to create the reports and dashboards that they need and organize it in a way that suits them.
If you are a Power BI admin or if you´re concerned with governance or security, you often want to know what´s going on in your Power BI environment. Since Power BI is first and foremost a self-service BI tool, Microsoft has not (yet) developed good, out of the box, monitoring tools. This means that you need to develop your own way of monitoring Power BI.
This series of blogs describe what you should be monitoring in Power BI and what method works best for each.
The blogs are:
Power BI Admin Portal Settings
Power BI Artifact Inventory
Power BI Activities
Power BI Capacities
We will start this blog series with looking at how you should monitor your Power BI Admin Portal settings.
Part 1. Power BI Admin Portal
The Power BI Admin Portal is the place where the Power BI Admin can change settings and monitor certain things.
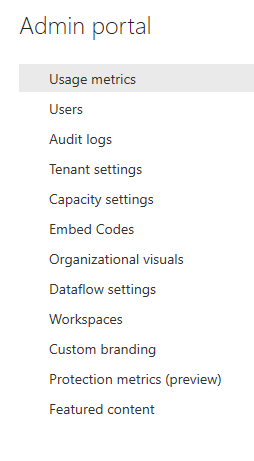
One of the main points of interest is the Tenant settings. Some of the settings that you can change in the Tenant settings part of the portal are who can publish to web, who can share externally, who can create workspaces and where the internal help portal is. There are in all, at the time of this writing, 31 settings you can change. Some of them are fine in the default settings while others like Publish to web should be changed as soon as possible.
Besides the Tenant Settings some of the other things you can change are Capacity Settings, Dataflow Settings, look at all workspaces in the tenant, turn on audit logs, brand the Power BI portal, manage Protection metrics and add Featured content. What ever you decide to change the purpose of this blog is to encourage you to document and monitor the settings
Figure 2: Power BI Admin Portal
Record and monitor Tenant settings
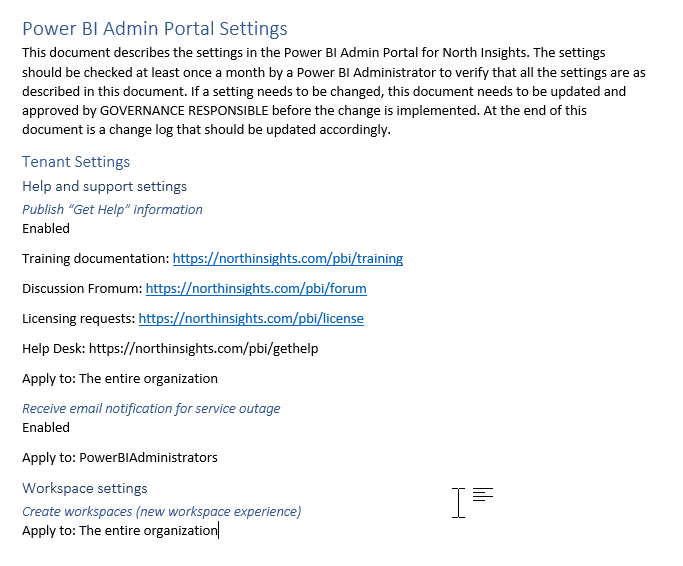
It´s very important that the Tenant settings are documented and monitored regularly. Unfortunately, you cannot monitor these settings automatically, so someone needs to login to the portal and manually check the settings. We recommend that you write down all the settings and have the admin check them once a month. This is especially important if you have more than one administrator. The main reason for that is that any change made in the portal is not logged anywhere you can access. If you have not written down how you want the settings to be, it´s very difficult for an admin to know if the settings are correct as they cannot see if they have been changed unless they remember the previous setting.
Figure 3: Example of Power BI Admin Portal Settings documentation
Besides the Tenant settings we recommend that you turn on Audit logs which are needed for activity monitoring and review Embed codes to make sure there is no sensitive data being embedded outside of an approved system. If you have Power BI Premium you can also use the Capacity settings to control your capacities.
Conclusion
Go through all the settings in the Power BI Admin Portal. Change the settings as needed and then documents every setting. Manually monitor that the settings have not been changed at least once a month as a part of your governance process. Turn on Audit logs and make sure there are no reports being embedded outside of approved systems.
Come back for the next blog on Power BI Artifact collection and monitoring
If you want to discuss Power BI monitoring or governance or get help with implementing it in your organization please contact Ásgeir Gunnarsson on asgeir@northinsights.com or go to https://northinsights.com and find out what we offer and how to get in touch. We offer consulting and advisory as well as training on the whole Business Intelligence lifecycle including Power BI.
Power BI, like many other self-service BI tools, suffers for its dual purpose of being self-service but also used as an enterprise BI tool. Power BI started out as a pure self-service tool but has increasingly been moving to be more of an enterprise tool and can rightly be called a hybrid BI tool. No matter if you use Power BI as a self-service tool, as an enterprise BI tool or both, it’s important to include governance into your implementation. Far too many organizations start using Power BI without thinking about governance and then have the problem of trying to get their users to stop doing things as they are used to, and to start using process they are not used to and often feel will hinder their progress.
No matter if your organization is starting its Power BI journey or has already ventured in the Power BI “Wild West”, governance is an important and necessary part of any Power BI implementation.
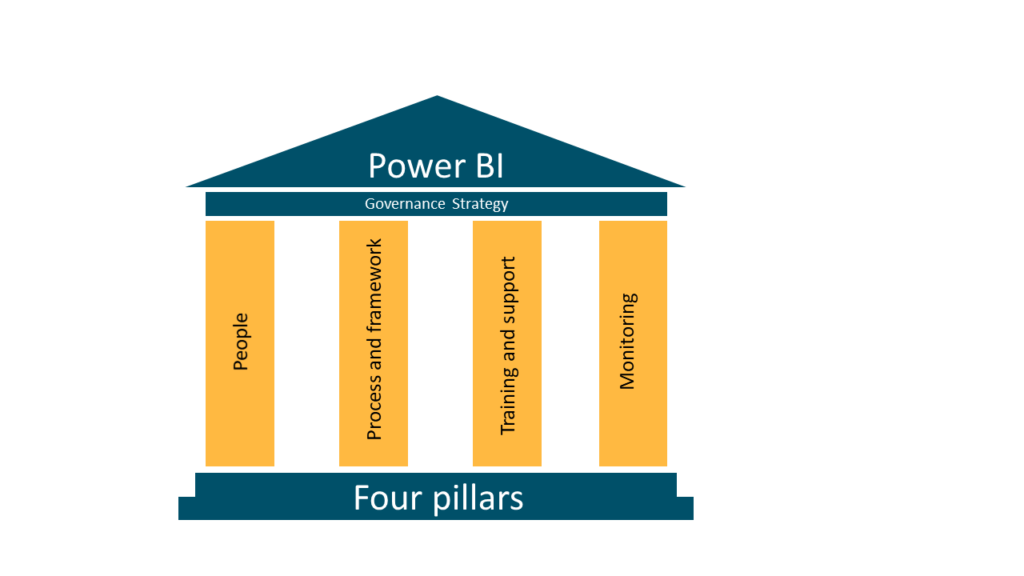
This article will focus on the 4 pillars of a good governance strategy:
Figure 1: The Four Pillars of Power BI Governance Strategy
Process
At the heart of a governance plan are processes. There can be many smaller processes or few bigger ones but without them there is not much governance.
It´s important to have a formal governance process in place. This process is often broken down into smaller processes and usually contains processes for Development, Publishing, Sharing, Security, Naming standards, Support and Tenant Settings.
Most often these processes describe how to work with Power BI and sometimes they describe how to support Power BI. It´s vital that the processes are easily discoverable and are setup as a part of a whole so that users will know how each process ties into the whole governance strategy. One way is to have one master process document with links to all the process documents. Another way is to store all the process documents in the same library and categorize them so it´s easy to navigate between them and they are logically grouped.
We will look at the seven most common (in the our opinion) processes and see examples on what they might contain.
Development process
A development process most often describes how a report, datasets or both are developed. They describe where you develop the Power BI content and how you store and version your files.
Publishing Process
The publishing process usually describes how to set up multiple environments and how to promote Power BI content between them.
Sharing Process
The Sharing process describes how to share reports, dashboards and datasets and links to the security process for more details.
Figure 2: Example of a sharing process image
Security Process
A security process describes how to secure Power BI content. This is usually split into two categories: Object level security and data security.
Naming standard process
One of the most undervalued process is the Naming Standard process. Having this process early in the Power BI implementation will greatly improve the usability of the Power BI environment. Finding workspaces, reports, dashboards and datasets can be very tricky when you have hundreds of workspaces with no clear naming convention.
Support process
Many organizations neglect to create a proper support organization when implementing Power BI (see Roles section). Having a good support process will enable your current support organization or dedicated Power BI support people to more easily assist users when needed. A support process will help non-Power BI supporters to know when to dig in and try to solve a problem and when to refer the problem to the report owner or Power BI Support people.
Tenant Settings process
There are several settings in the Power BI admin portal that are important when it comes to governance. Publish to web, Sharing outside of organization, Export data, Internal support page to name few are all very important for different reasons. As there is no way to monitor the tenant settings automatically, it´s very important that the organization has a process in place defining how each setting in the Power BI Admin portal should be set, who the setting should apply to and describe why it´s important.
Training
If you want to have a successful Power BI implementation training is very important. You want to train everyone who touches Power BI but in a different way depending on their role. You want to make sure you get to everyone and deliver the right training based on their needs. It´s not only governance training that is important. Training users in properly using Power BI and using best practices will deliver value faster and will make report and dataset developers more compliant.
One of the things we have been exploring is to automate the training offer to users by using Microsoft Flow in combination with Office 365 (who has license) and the Power BI activity log (what are they doing). When a user gets a license or when they publish their first report or dataset they receive an email with the training being offered in the organization as well as relevant document and processes needed for their role.
Training categories
The most common training categories are Consumer, Report Developer and Report and Dataset Developer. For each category there is a definition of who belongs to it as well as what training content is appropriate and how it should be delivered. Most often the Consumer training is delivered either as videos or training manuals. Developer training is most often either classroom training or online training course.
Monitoring
One of the cornerstones of governance is monitoring. Monitoring what users are doing and monitoring what users are creating. From a governance perspective monitoring creation, access, usage, changes, deletion and data exports are the most important. Besides that, monitoring the settings of Power BI Admin Portal is very important.
The Power BI Rest API can tell you what artefacts exists and who has access to what. Besides that, the Rest API has powerful administration endpoints that allow you to get information about various administration objects as well as allow you to perform admin tasks. To access the Power BI Rest API, you can either create your own web application and call the API or you can use PowerShell to call it. Microsoft has put some effort into wrapping many of the endpoint in the API into PowerShell cmdlets and they have also created a cmdlet to wrap the call to the Rest API. You can read more about the PowerShell cmdlets at https://docs.microsoft.com/en-us/powershell/power-bi/overview?view=powerbi-ps and you can read more about the Power BI Rest API at https://docs.microsoft.com/en-us/rest/api/power-bi/. The user will have access to some of the endpoints through normal Power BI workspace access, but a lot of the endpoints require the user to be a Power BI administrator, at least if they want tenant level information.
Monitoring usage
The Power BI Activity log can tell you who accessed what and who changed or deleted what. The Power BI activity log is turned off by default but can be turned on in the Power BI Admin Portal. The activity log can be accessed in two places:
Power BI Rest API
The last 30 days of the activity log is now replicated from the Office 365 Security and Compliance to the Power BI admin portal and you can get to that with the Power BI Rest API if you are a Power BI admin.
In the Office 365 Security and Compliance
The activity log is part of the Office 365 Security and Compliance Centre. To get access to the activity log in the Office 365 Security and Compliance Centre you need to have the View-Only Audit Logs or Audit Logs role in Exchange Online or be an Office 365 admin. It is possible to fetch data from the Office 365 acitvity log in two ways. One is to log into the Office 365 Security and Compliance Centre, run the log query and either view the results on the screen or download the results as a CSV file. Another way is to use the Office 365 Rest API which is the preferred way if you want the automate the collection of the log information. Note that the log is only stored in the Office 365 Security and Compliance Centre for 90 days so if you want to keep it for a longer time you will need to collect it and store it in a different place such as data warehouse. More information about the acitivty log and how to collect the data can be found here: https://docs.microsoft.com/en-us/power-bi/service-admin-auditing.
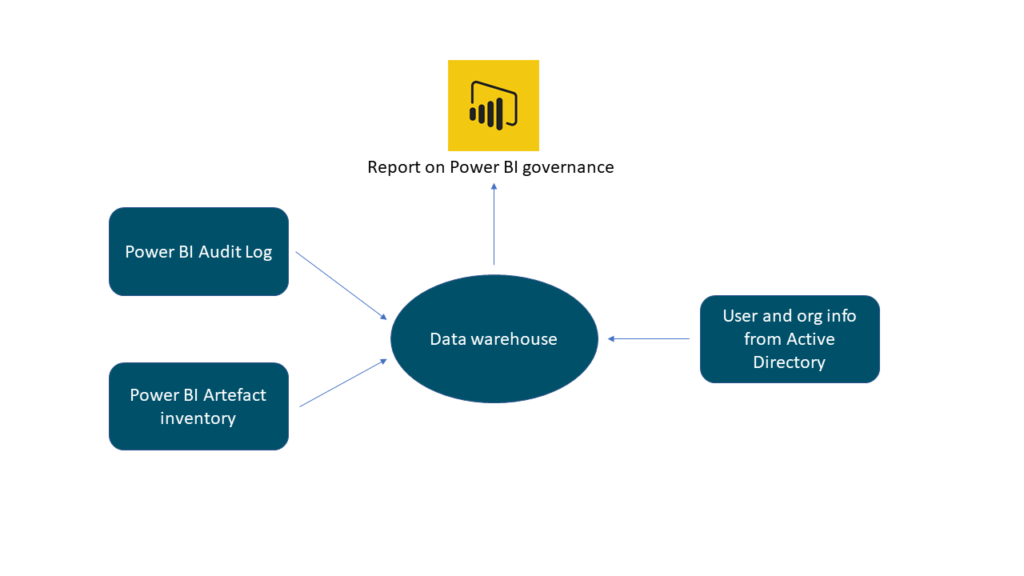
We recommend that both the activity log and artefact inventory is collected and stored in a database. Partly because of governance issues as described before but partly because there is valuable information in there about adoption, development over time and user behavior which could be beneficial for the organization at a later time.
Figure 3: Monitoring Power BI strategy
Monitoring Power BI Admin Portal
There are several settings in the Power BI Admin Portal that are very important when it comes to governance. One of the main points of interest is the Tenant settings. Some of the settings that you can change in the Tenant settings part of the portal are who can publish to web, who can share externally, who can create workspaces and where the internal help portal is. There are in all 31 settings you can change. Some of them are fine in the default settings while others like Publish to web should be changed as soon as possible.
Besides the Tenant Settings some of the other things you can change are Capacity Settings, Dataflow Settings, look at all workspaces in the tenant, turn on audit logs and brand the Power BI portal.
Figure 4: Power BI Admin Portal
It´s very important that the Tenant settings are documented and monitored regularly. Unfortunately, you cannot monitor these settings automatically, so someone needs to login to the portal and manually check the settings. We recommend that you write down all the settings and have the admin check them once a month. This is especially important if you have more than one administrator. The main reason for that is that any change made in the portal is not logged anywhere you can access. If you have not written down how you want the settings to be it´s very difficult for an admin to know if the settings are correct as they cannot see if they have been changed unless they remember the previous setting.
Besides the Tenant settings we recommend that you turn on Audit logs which are needed for activity monitoring and review Embed codes to make sure there is no sensitive data being embedded outside of an approved system. If you have Power BI Premium you can also use the Capacity settings to control your capacities.
At the time of this writing there are 91 events that are monitored in the Power BI audit log. If your organization does not want to store all that data you should consider taking all events that are about viewing, editing (including deleting) and exporting. When you have started the collection of the data you might want to join it to further information from the artefact inventory discussed in the previous section as well as information about the organization employees and the organization structure.
Monitoring the Power BI On-Premise Gateway
The Power BI On-Premise Gateway is a Windows service running on an on-premise server. The gateway needs to be monitored as other Windows services. The main things to monitor are the service uptime and server performance. Normally monitoring is in the hands of an infrastructure team (if one exists).
Roles
To be successful with a Power BI implantation in the long run it´s important to have well defined roles. This is most likely different from organization to organization and in some cases the same person might have more than one role. The most common roles are Power BI Administrator, Power BI Gateway Administrator, Data steward, Power BI Auditor and Power BI Supporter(s).
Automation
For the training and processes you can automate the discoverability by sending content to users as soon as they get a license or as soon as they create content. That way you are sure that all your users are aware of the processes and training and you can control what they receive depending on where they are in their Power BI journey.
Summary
This article suggest that a good Power BI governance strategy has 4 pillars, Processes, Training, Monitoring and Roles. Organizations need to define processes so that their users do Power BI right, train them to follow the processes as well as best practices when it comes to Power BI, Monitor the Power BI environment and have defined roles and responsibilities. Each pillar has equal importance and for a successful Power BI implantation you want to make sure you think about them all.
Governance is a necessary part of a Power BI implementation and the earlier you can start the easier it will be.
If you want to discuss Power BI governance or get help with implementing it in your organization please contact Ásgeir Gunnarson on asgeir@northinsights.com or go to http://northinsights.com and fill out the contact form. We offer consulting, training and advisory on the whole Business Intelligence lifecycle including Power BI.
We have been considering many options when it comes to how we can incorporate glossary information into our Power BI reports. We have started the work of creating master data around our glossary and are considering how best to get it into our cubes.
When Microsoft announced the tooltip pages for Power BI I saw that this could be the way we display the glossary in our reports. So, while we solve the problem of getting the glossary into the cubes I decided to try to add the glossary manually to a tooltip page to see how it looks.
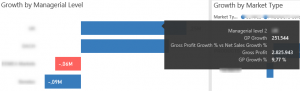
Traditionally we have been showing support measures in the tooltip. An example of this is when Net Sales Growth is in a graph the tooltip would show Net Sales and Net Sales Growth %. I really like how you can for most visuals put in multiple tooltip measures, but my problem has been that everything in the visual is displaying in the tooltip. For an example we sometimes include a measure only meant to colour the graph. This can be a Net Sales vs. EBTIDA measure or something like that. This measure is not meant for displaying in the graph but because you don‘t have any control over the tooltip it is displayed.
With the tooltip page you have full control over what you display and what you don‘t and you get more space to work with. In the images below, you see that when looking at Gross Profit Growth in a graph we were displaying the Gross Profit and Gross Profit Growth and are using Gross Profit Growth % vs Net Sales Growth % to colour the graph. This is nice enough but the extra colouring measure is annoying and you are, in my mind, missing the definition of Gross Profit.
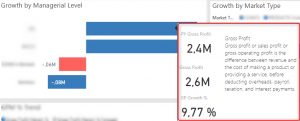
Below you see an image of how we are now doing using the new tooltip pages. Here we are showing prior year Gross Profit, current period Gross Profit, the Gross Profit Growth % and the definition of Gross Profit. Now many of you might feel the definition is not important but when you work in a multinational company the definitions often become important. While the definition of Gross Profit is simple the definition of measures such as Cost of goods sold (COGS) can be complicated and so it‘s is important that everybody knows exactly what definition is used.
This is of course just the start and I see plenty of opportunity to relay more messages to the users via the tooltip page. This can be definitions of calculations where appropriate or dimension definitions.
I had a rather odd experience this week. We are rolling Power BI out in the company I work for. We have a big investment in SSAS MD and that is not about to change. So I have been creating reports on top of SSAS MD for the last month or two with reasonable success. We are starting with a single cube and from the beginning number formatting was not recognized by Power BI. I assumed this was one of many things Power BI didn’t do well from SSAS MD so we tried to work our way around the problem. We used VBA functions in the cube script to limit measures to single decimal and we multiplied ratios by 100 to show percent. This was ok but not very good. Then we found a bad side effect with the VBA function which was that Excel pivot tables couldn’t recognize empty cells when using measures formatted with those functions. So I really starting looking into if Power BI couldn’t do number formatting from SSAS MD. It turns out that Power BI can do it but it just didn’t work for us. I tried few of our other cubes and while it didn’t work in the first couple cubes it did in some others.
I got a tip from Koen Verbeeck (twitter) about an article by Chris Webb (twitter) (article) explaining that while Power BI did recognize number formatting from SSAS MD if you changed the number format in a scope sentence Power BI wouldn’t recognize it any more. I read the article but couldn’t link that to our problem as we didn’t change any number format in scope sentences and not only some of our measures were missing number formatting, but all of them.
But the article got me thinking if our script could be the problem. We had quite few scope sentences in our script so I decided to start by deleting all scope sentences from the cube and see if Power BI recognized the number formatting then. And to my surprise it worked. I then decided to put them all in one by one to see where it went wrong. After some back and forth I managed to conclude that our time intelligence script (DateTool by SQLBI) and one other custom scope sentence (working on a dummy dimension) where to blame. Both these scripts were at the bottom of the script. What did the trick in the end was to take these two scripts and move them above the measures and all of a sudden Power BI recognizes the number formatting.
I now have the task of removing all the extra measures from the cube and change all the reports to use the normal measures instead of the special measures we had created to go around the problem.
If you are using Power BI on top of SSAS MD and don’t get the number formatting through. Take a hard look at your scope sentences and see if you need to either change them or move them around in your script.
Now it’s one week since SQL Saturday Iceland 2017 finished and I’m almost recovered. It was a blast like last year but I enjoyed this one a bit more as I feel we were better prepared and knew more what we were facing. Before last year I had only attended SQL Saturdays as a speaker and an attendee and even though you feel you can sense some of the work that goes into the preparations you still don’t know until you do it. But it’s not only work and worries organizing a SQL Saturday. There is a lot of fun, new friends and learning to be had from it if you put in the effort. The organizing team had great fun together, I met a lot of lot of speakers, some for the first time others again and this experience of organizing such a big event will help me in my future endeavors.
We had two pre-cons on the Friday which we had record attendees at. We also broke our record on the Saturday with just over 100 attendees. There was still 1/3 no shows so that’s something we need to work on. But I’m very pleased with how the event went. We had three tracks and the attendees were usually split nicely between those 3 tracks and everyone I met in the breaks were happy with what they saw and heard. We had 19 great speakers that took the journey to Iceland to speak and we are so appreciative of them. They are the key to this event being a success and their willingness to share their knowledge and time is so fantastic to such a small and isolated community as Iceland is. The venue was also great. All the equipment worked really well and the rooms were perfect for this size of an event. It didn’t hurt that you could see the snow falling in the un-spoilt nature through the big windows in the rooms.
We also had great sponsors. Some were there for the first time while other have been with us from the start. It is fantastic to see such great backing for the SQL community and we are very thankful that our sponsors made this event possible. I really hope they got something out of it as well as we want this to be a win-win for all included.
At last I just want to say thank you to the organizing team and other volunteers that worked hard both on the day but also during the weeks leading up to the event. I’m already looking forward to next year but before that I have some events to attend both as speaker and also as an attendee. More about that soon.
I had a odd experience at work. While waiting for more Power BI licenses I decided to send couple of Power BI Desktop files in an email to few colleagues that didn’t have licenses yet. We are also experimenting with Microsoft Teams (another post coming about that soon) so the email was rather long with explanation about how to install Teams and Power BI desktop as well as description of the Power BI files. In the email I asked them to contact me if they needed any help. A week later I hadn’t gotten any feedback and started to wonder if nobody of them was trying it out. I then got a request for help from one the people that got the email. When I started to help them out it came into light that he hadn’t received the email at all. I try to resend it but while it looked like it had been sent on my end he didn’t receive anything. We had previously sent email with .pbix fiels in attachment without any problem. We called in help from a system administrator and he found out that the emails had been stopped by a rule that stopped emails with amongst other .js, attachments without any warning to either receiver or sender. As many of you might know the .pbix file is a compressed collection of files needed for to create a report. It turns out that Exchange opens up the collection and looks inside and if you have custom visuals in your report it will find a .js (JavaScript) file. You can look inside your .pbix file to see what is inside by copying it and then change the extension to .zip. You can then open the collection and look inside to see what files are in there.
So be aware that if you have Power BI Desktop report with custom visuals you might have problems where there is a JavaScript filter. If you send .pbix files in an email make sure that the receiver gets them as many companies have these kind of filters in place with good justification. You don’t want people sending malicious code in JavaScript format in email.